Deupe
Help build better trust and reliability within your data.
Deupe is application built on the Dedupe python library which leverages machine learning to perform deduplication and entity resolution across large datasets.
Users can recognize and link information tied to specific entities across multiple data silos, clean data sources and even enrich data sources allowing for higher quality of data to ultimately help strive towards a single source of truth.
The Problem
Poor data management is both risky and costly.
“In 2016, IBM estimated that poor data quality costs organizations and business $3.1 trillion alone in the U.S.”

Data is leveraged in everyday work and managing data quality is often lumped into being as ‘part of the job’. Resources are often correcting or fixing data on the go with out correcting it at the source.
Duplicate records can incur additional storage expenses on Cloud providers such as Azure, AWS or GCP where memory dictates the price.
Duplicate records can create additional computational costs through ETL jobs.
Duplicate records can eat up productive labour, as users of data will require to accommodate bad data in their work. This is also referred to as “shadow data quality”.
Duplicate records can be costly by erroneously influencing our decision making through misleading KPIs and reporting errors.
The Project
Deupe was a proof of concept to be incorporated as a microservice within the enterprise. Outside of an API interface, the Data Sicence team also needed to have the business be able to use the microservice and required design that allowed users to interface with their algorithms in a easy, simple and accessible manner.
My Role
Product Designer, UI/UX design, Visual Designer, Interaction Designer
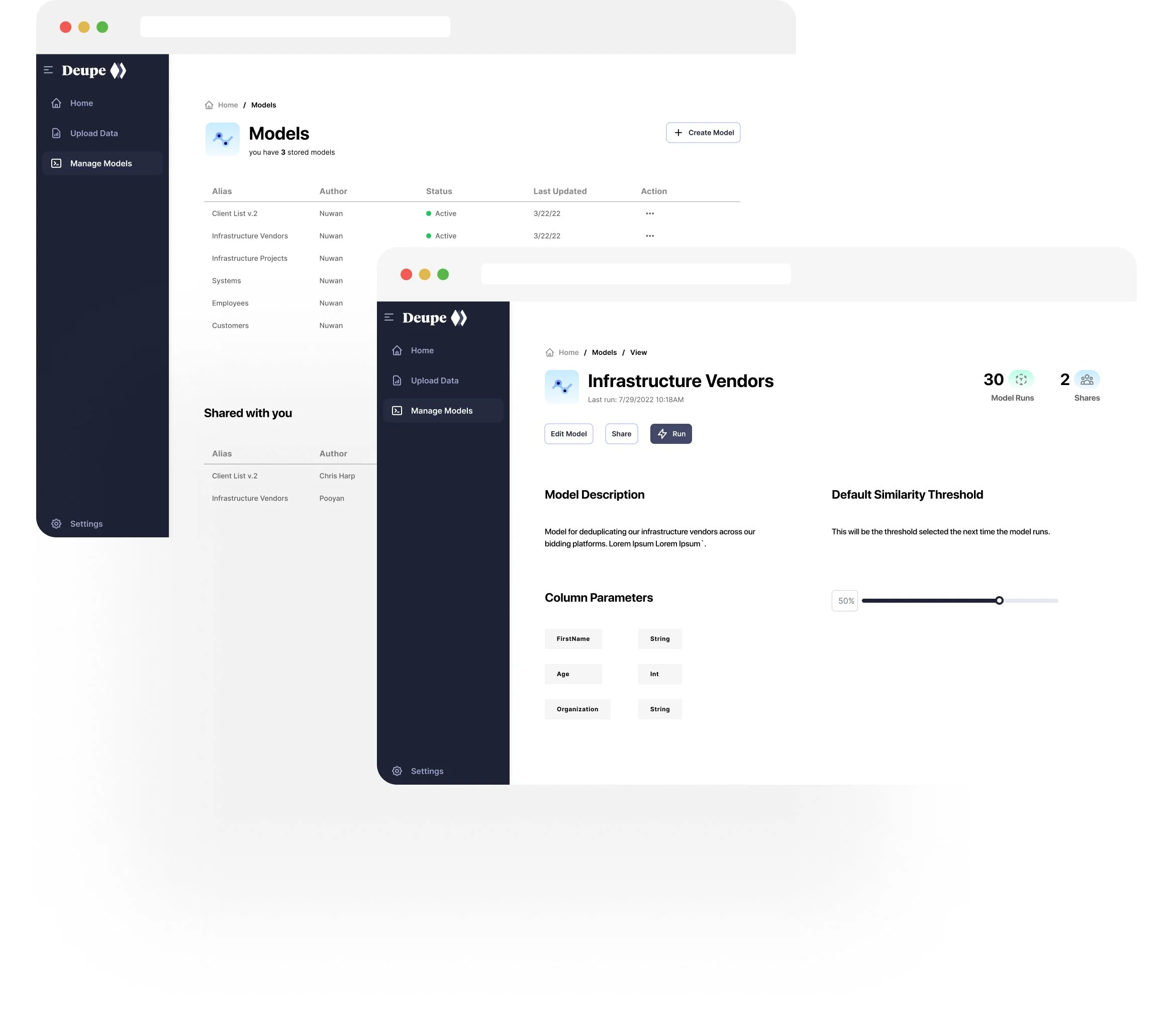
The Solution
Deduplicate your data to ensure better & reliable data quality.
The Protoype
Interact with the Protoype below:
